はじめに
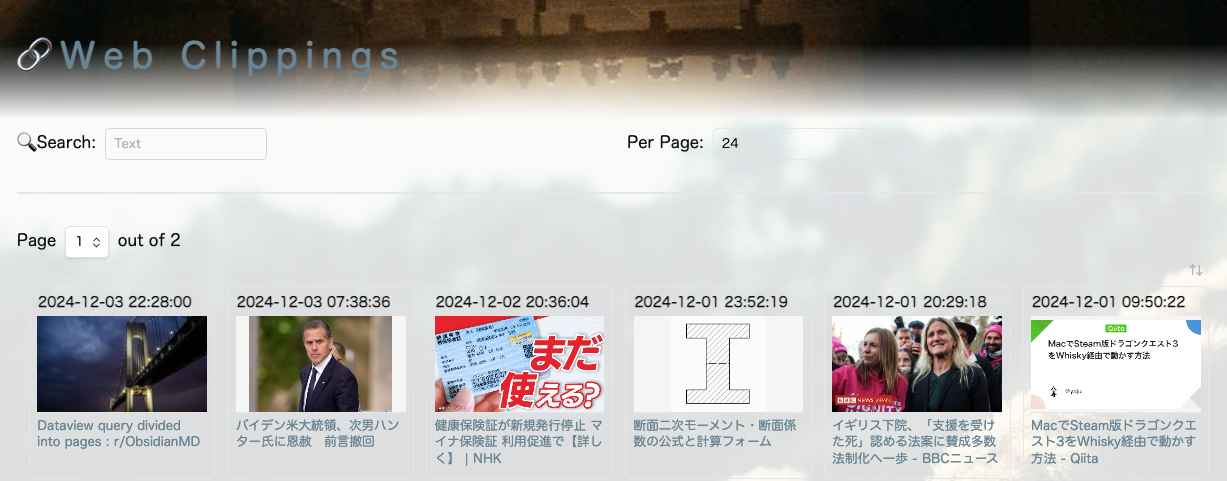
タイトル通り、ObsidianのDataviewにページング機能を追加する。
Dataviewのdefaultの機能ではクエリに引っかかったノート一覧を全て表示するか、limitを設定して上位n個を表示するしかできない。
全て表示だとノートが多い時にとても重くなるし、limitだと後半のノートは表示できなくなるという問題がある。
issuesにも上がっているが、随分前からあるissueのようで対応には期待できない。Dataviewの後継プラグインのDatacoreが開発中で、そちらにはページング機能が搭載されるらしいが、まだリリースはされていない。
調べると、redditにMeta Bindを使用した解決策が載っていたので導入することにした。
導入手順
引用元のコードは下記
const pageNum = dv.current().page;
const start = 10 * (pageNum - 1);
const end = 10 * pageNum;
const results = dv.pages();
const totalPages = Math.ceil(results.length / 10);
const options = results.slice(0, totalPages).map((_, i) => `option(${i + 1})`).join(',');
const selector = `\`INPUT[inlineSelect(${options}):page]\``;
dv.span(`Page ${selector} out of *${totalPages}*
`);
const rows = results.slice(start, end).map(p => [p.file.link, p.file.ctime]);
const cols = ['File', 'Created'];
dv.table(cols, rows)なるほど。シンプルで良さそう。
これを📘Obsidian WebClipperを導入してみたで作成したテーブルに追加したいが、Dataviewjsが必須のよう。
今回の様に書き方を変えたいだけの場合は生成AIで8割行けるので、前記事のクエリをchatGPTに変換してもらい、それを修正したうえでページングロジックを追加した。
// フロントマターの設定
const search = dv.current().search || ""; // 検索クエリ(デフォルトは空文字)
const perPage = dv.current().perPage || 10; //1ページの件数(デフォルトは10)
// データを取得し、条件でフィルタリング
const results = dv.pages('"Clippings"')
.where(p => {
// 検索条件がない場合は全て通過
if (!search) return true;
// フィルタ対象のフィールドを取得
const fields = [p.title, p.description, p.author].filter(Boolean); // nullやundefinedを除外
// icontains相当: 小文字で部分一致を検索
return fields.some(field =>
typeof field === "string" && field.toLowerCase().includes(search.toLowerCase())
);
})
.sort(p => p.file.ctime, "desc") // 作成日時で降順ソート
// ページングロジックを追加
const pageNum = dv.current().page;
const start = perPage * (pageNum - 1);
const end = perPage * pageNum;
const totalPages = Math.ceil(results.length / perPage);
const options = results.slice(0, totalPages).map((_, i) => `option(${i + 1})`).join(',');
const selector = `\`INPUT[inlineSelect(${options}):page]\``;
dv.span(`Page ${selector} out of ${totalPages}
`);
// 結果をテーブル形式で表示
dv.table(
["Time", "Image", "Link"], // テーブルの列ヘッダー
results.slice(start, end).map(p => [
moment(p.file.ctime.toString()).format("YYYY-MM-DD HH:mm:ss"), // 作成日時をフォーマット
p.image
? `` // 画像がある場合はMarkdown形式で表示
: ``, // プレースホルダー画像
`[${p.title || p.file.name}](${p.file.name})` // タイトルまたはファイルリンク
])
);完成
おわりに
また一つ便利になりました。